PaperReading | TinyLFU A Highly Efficient Cache Admission Policy
缓存是计算机科学中用于提高系统在多个领域的性能的最基本和最有效的方法之一。缓存起作用的直观原因是数据访问多计算机科学领域表现出相当程度的“局部性”。 更正式的捕获方式这个“局部性”是通过概率分布来表征所有可能的数据项的访问频率,并注意到在计算机科学的许多领域中,概率分布是高度倾斜的,这意味着少数对象比其他对象更有可能被访问对象。 此外,在许多工作负载中,访问模式以及相应的概率分布,随时间变化。 这种现象也被称为“时间局部性”。
鉴于缓存大小通常是有限的,缓存设计者面临着如何选择项目的困境存储在缓存中。特别是,当为缓存保留的内存变满时,决定哪些项目应该从缓存中逐出。显然,驱逐决定应该以高效的方式进行方式,以避免需要回答的计算和空间开销的情况这些问题超过了使用缓存的好处。缓存机制使用的空间为了决定哪些项目应该被插入到缓存中,哪些项目应该被驱逐称为缓存的元数据。
当数据访问模式的概率分布随时间恒定时,最不常用 (LFU) 产生最高的缓存命中率 根据 LFU,在大小为 n 个项目的缓存,在每个时刻,迄今为止最常用的 n 个项目都保存在缓存中。然而,LFU 有两个明显的局限性。 首先,LFU 的已知实现需要维护大量和复杂的元数据。 其次,在大多数实际工作负载中,访问频率会发生根本性变化。依赖于“时间局部性”属性的 LFU 的流行替代品被称为最近最少使用(LRU,最后访问的项目总是插入到缓存中,最近最少的被访问的项目被逐出(当缓存已满时)。 LRU 可以比LFU1 并自动适应数据访问模式的临时变化和突发工作量。 然而,在许多工作负载下,LRU 需要比 LFU 大得多的缓存才能获得相同的命中率
TinyLFU的整体架构
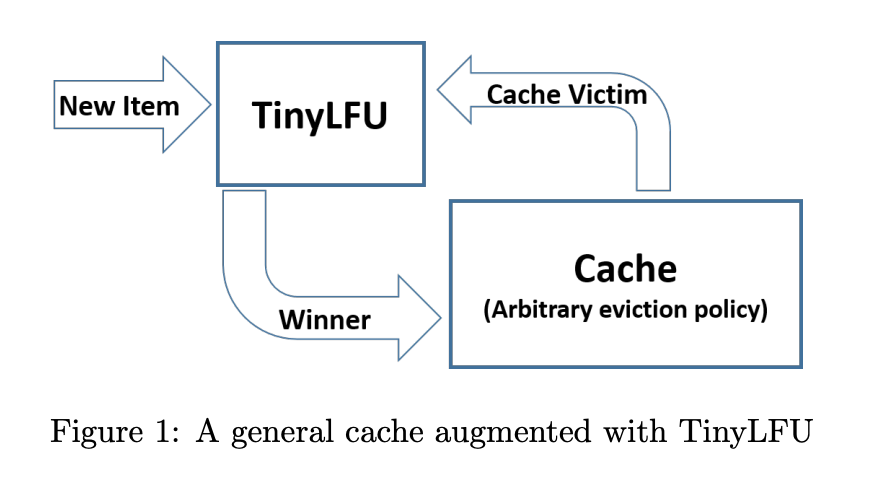
TinyLFU 是 LFU的一个变种算法 主要解决统计频率信息的开销 和 应对数据概率分布出现变化 应对突发性流量的的情况 , 经常访问的记录占用了缓存,偶然的流量不太可能会被保留下来,而且过去的记录在将来不一定会使用,这样就会一直占据缓存.就是论文中提到的数据保鲜机制为了使历史保持最新并删除旧时间 二是 内存的开销。
Count–Min Sketch
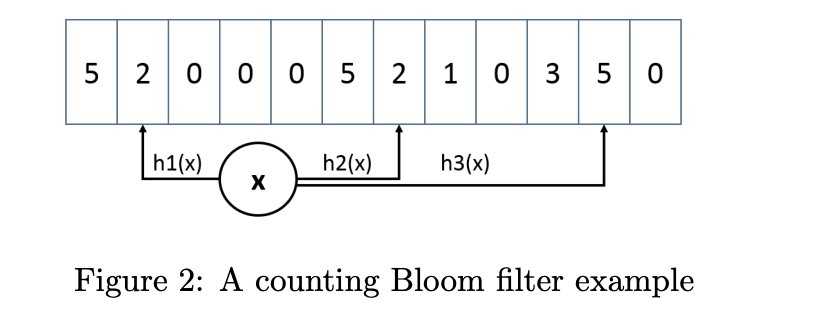
TinyLFU 提出使用Approximate Counting的方式,设计思想和BloomFilter的原理类似 不过 BloomFiler只有0和1,Count–Min Sketch 会对一个key进行多次hash后将 index到多个数组后的位置进行累加
数据的保鲜机制 就是去除过往频率很高但是不经常缓存 Caffeine有一个Freshness Mechanism 机制 就是统计当前的整体技术(当前所有的统计频率之和)达到某一个值 将所有的记录除2 其正确性论也给出了证明
Window Tiny LFU
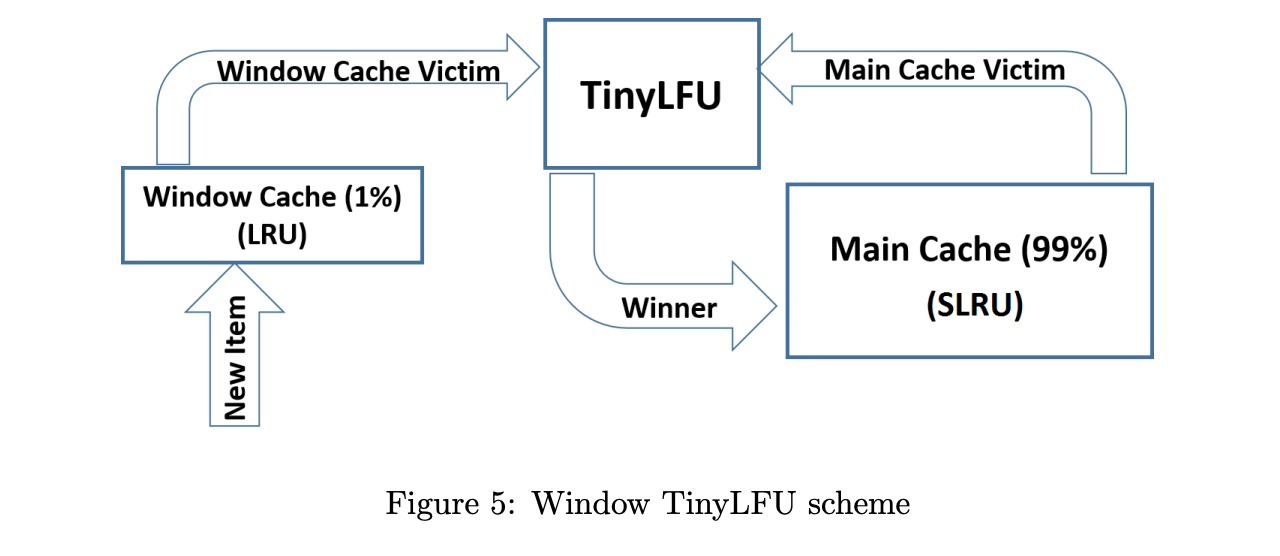
在 Caffeine Java 高性能缓存库 对 TinyLFU 进行了相关改进, 是因为在新记录还没有建立足够的频率就被剔除出去了 这使得命中率下降 Caffeine 设计了 一种 Window Tiny LFU 优化
包括两个缓存模块 主缓存是SLRU, SLRU包括一个 protected 和 一个 probation 缓存区。 通过增加一个缓存区(Window Cache), 当有新记录插入时,会先在window区,当window区满了之后 就会根据LRU把淘汰的数据放到probation区 如果protation区也满了,就把candidate 和 probation区要淘汰的元素进行比较, 胜者留在probation, 输者进行淘汰。